摩拜单车用户画像分析
任务说明
摩拜单车,英文名mobike,是北京摩拜科技有限公司研发的互联网短途出行解决方案,是无桩借还车模式的智能硬件。人们通过智能手机就能快速租用和归还一辆摩拜单车,用可负担的价格来完成一次几公里的市内骑行。
由于一公里的出行是一个高频的需求场景,所以mobike单车累计了大量的用户基本信息以及骑行的数据,通过这些数据,能够帮助企业更好识别自己的客群画像和他们的骑行偏好。
分析目标:
- 对用户数据和骑行数据用行探索分析(EDA)和可视化
- 使用Python建立聚类分析模型
- 对于聚类分析模型得出的分群特征进行解读
1 - 数据概况分析
1.1 读取数据
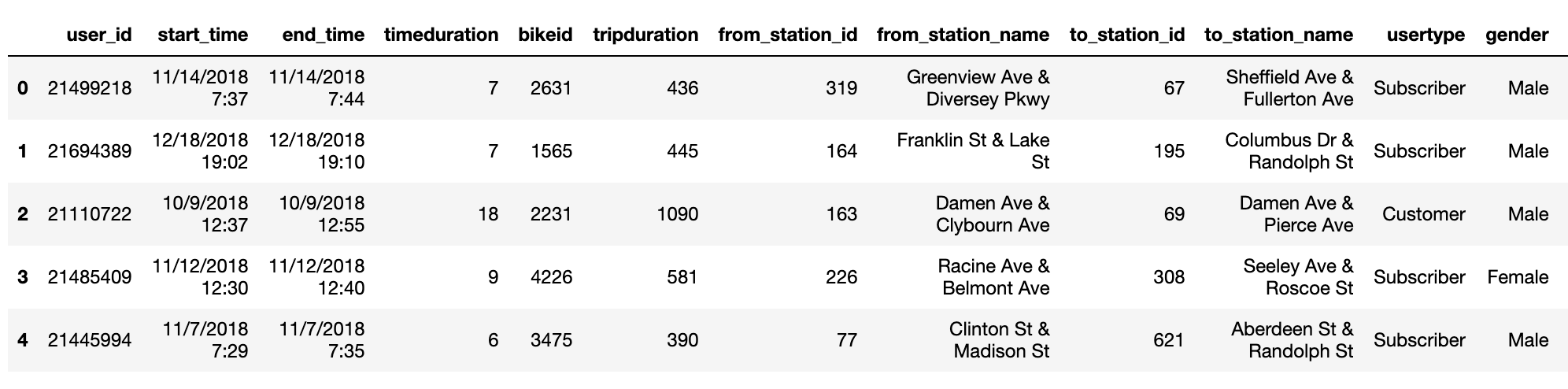
1.2 数据概况
数据字典
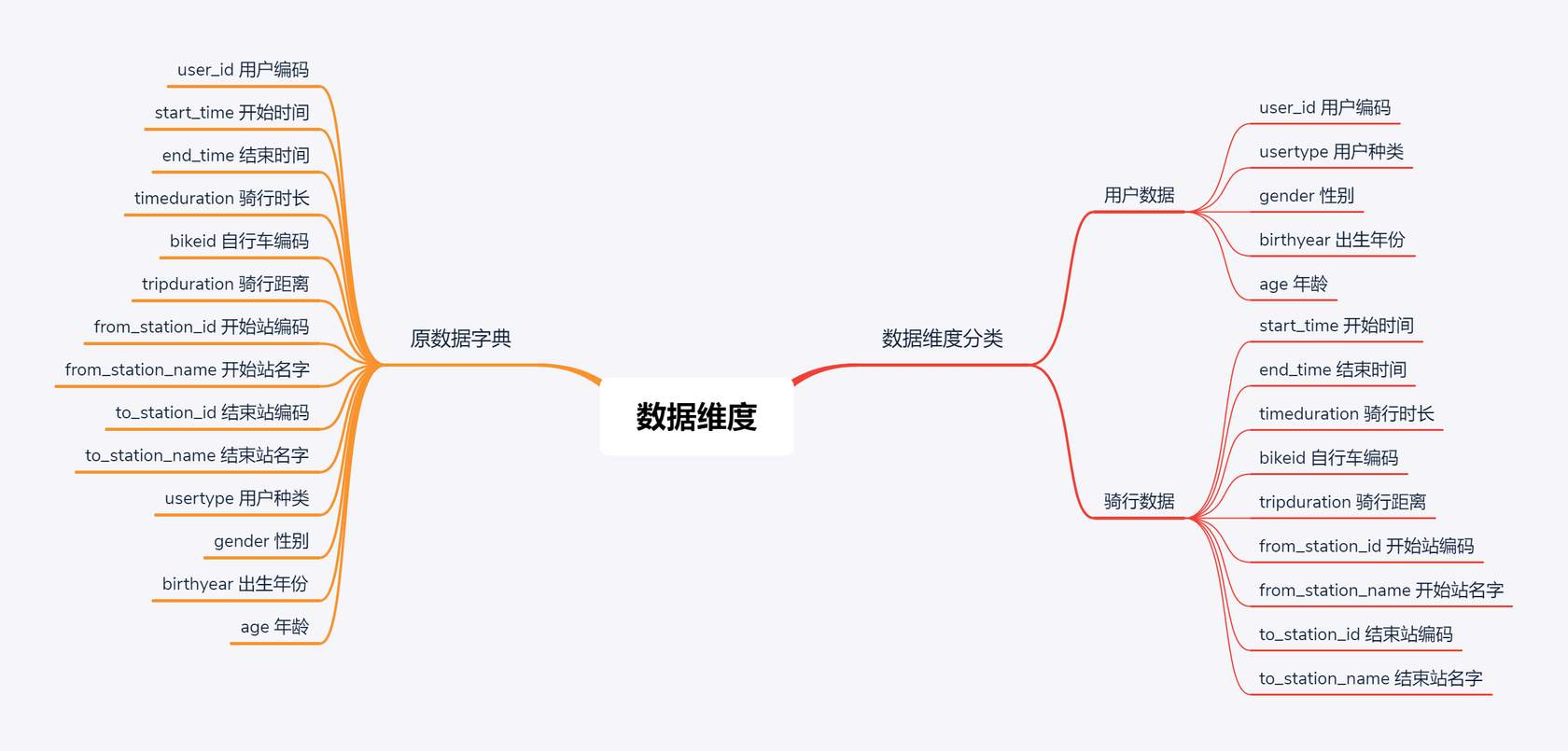
2 - 数据预处理
2.1 年龄
- 发现年龄缺失值,空值行数量较少,去掉
- 将年龄的数据类型进行转换
- 保留年龄小于80的数据
2.2 性别
- 仅有18个缺失值,删除
2.3 骑行时间
- 转化时间类型数据
- 创建计算字段
- 是否为工作日
- 是否是早晚高峰
2.5 骑行时长
- 检查骑行时长异常数据,存在 timeduration 计算错误的数据,同时 tripduration 也很长
- 重新计算骑行时长
3 - 探索性分析 (EDA)
3.1 年龄
plt.figure(figsize=(15,5))
sns.distplot(mobike['age'], bins=15, color='orangered')
plt.title("用户年龄分布", fontsize=15)
plt.show()
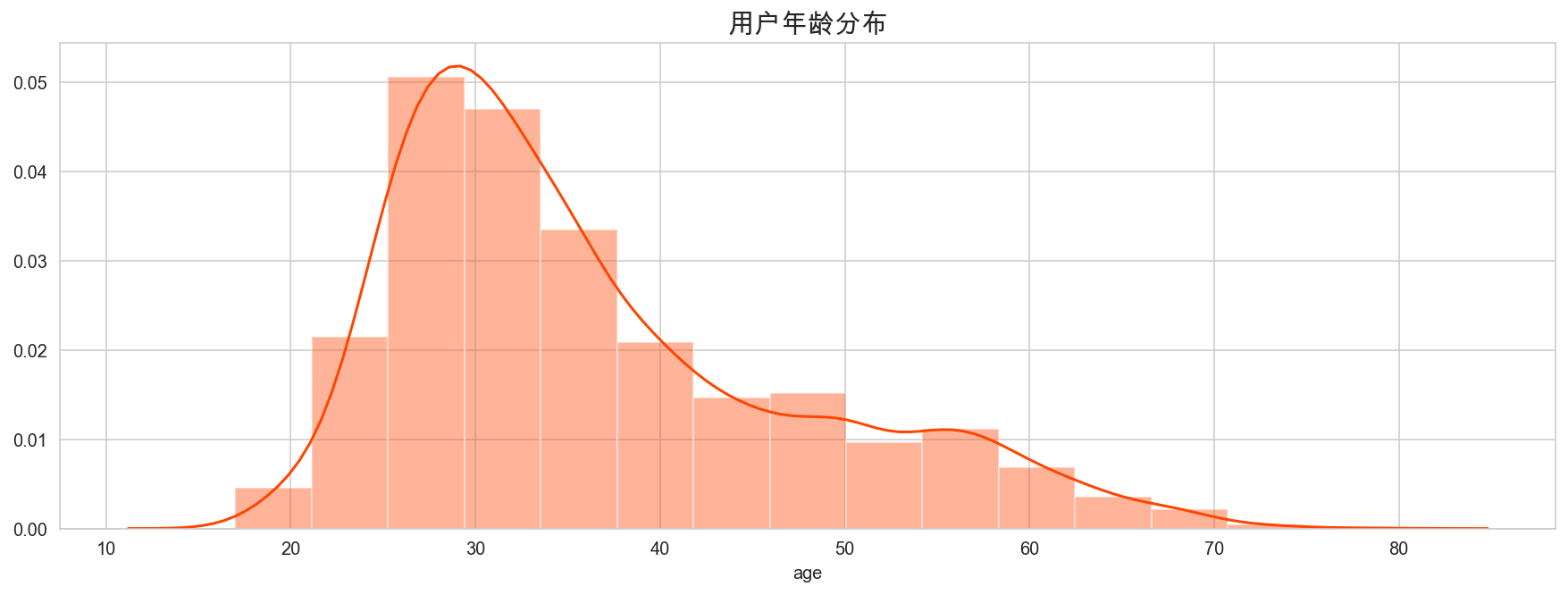
大部分用户集中在 25-35 年龄段
3.2 性别
plt.figure(figsize=(15,5))
sns.countplot(y='gender', data=mobike)
plt.title("用户类型分布", fontsize=15)
plt.show()
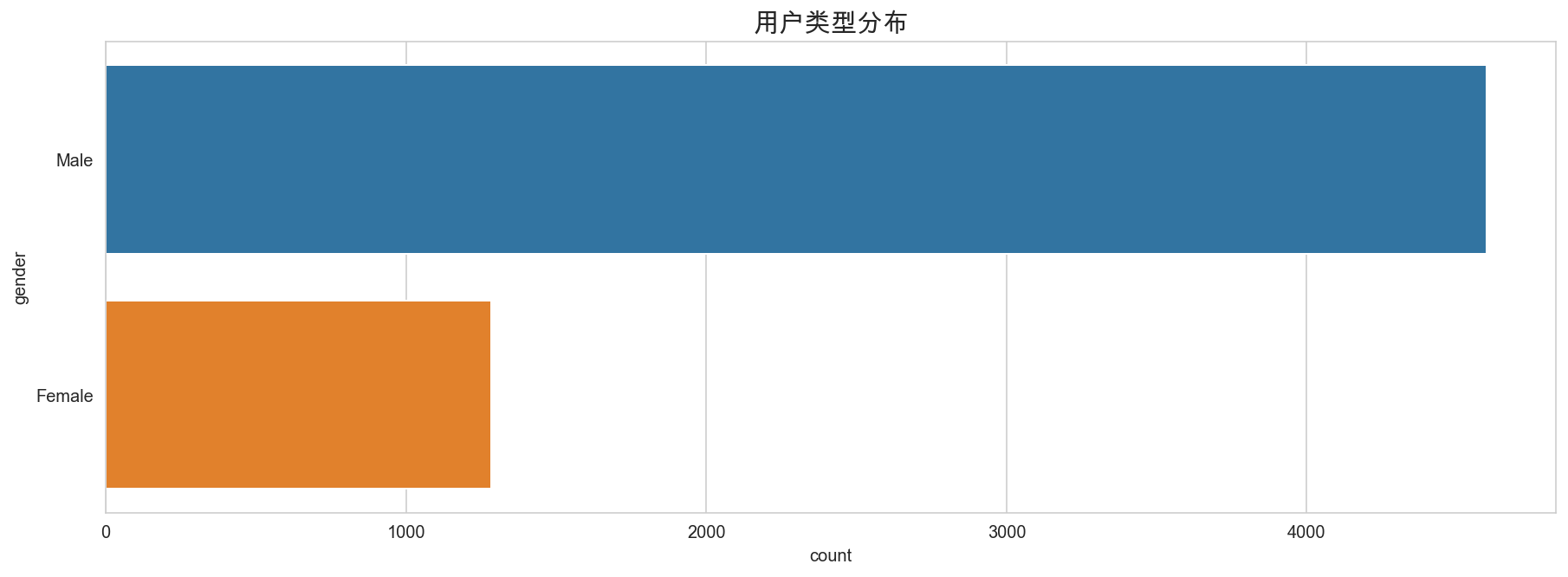
男性用户较多,约占 78%
3.3 用户类型
mobike['usertype'].value_counts()
Subscriber 5704
Customer 179
Name: usertype, dtype: int64
mobike['usertype'].value_counts(1)
Subscriber 0.969573
Customer 0.030427
Name: usertype, dtype: float64
plt.figure(figsize=(15,5))
sns.countplot(y='usertype', data=mobike)
plt.title("用户类型分布", fontsize=15)
plt.show()
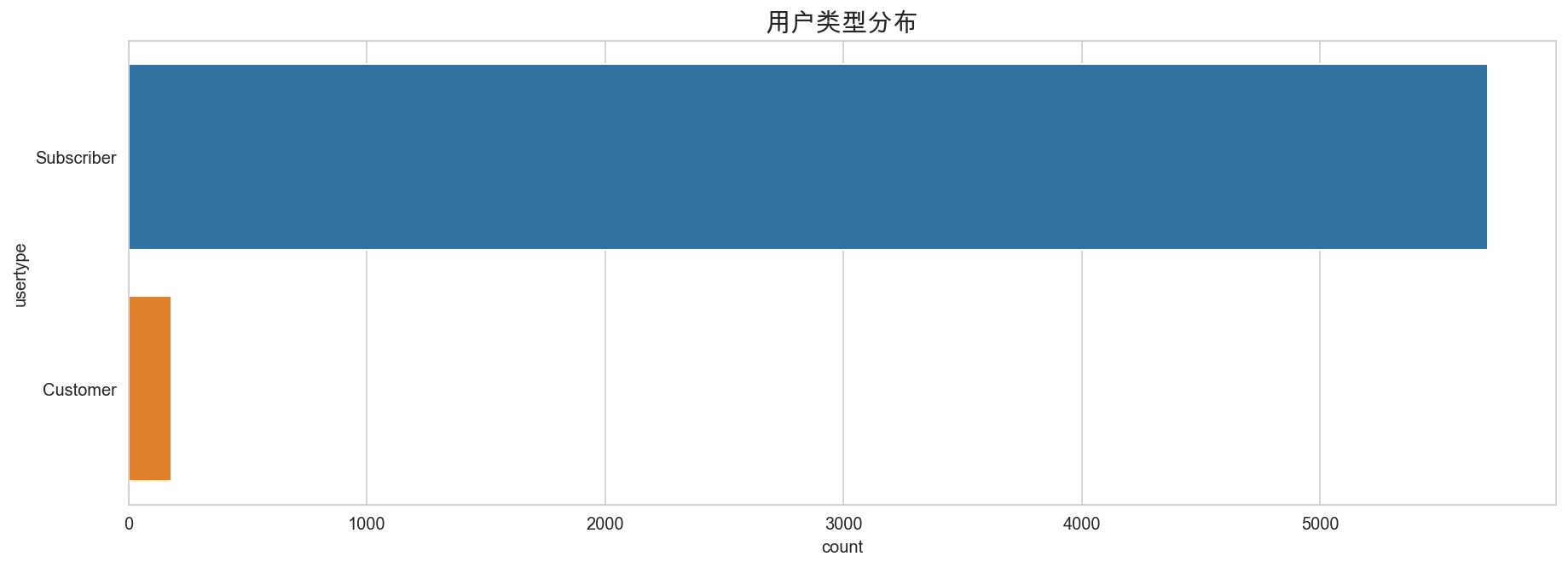
大部分为订阅用户,占 96.5%
3.4 骑行时间
# 查看骑行时间年的分布
mobike['start_time'].dt.year.value_counts()
2018 5883
Name: start_time, dtype: int64
# 查看骑行时间月份的分布
mobike['start_time'].dt.month.value_counts()
10 3107
11 1601
12 1175
Name: start_time, dtype: int64
# 查看骑行时间按天分布
plt.figure(figsize=(15,5))
sns.countplot(mobike['start_time'].dt.day, color='orangered')
plt.title("骑行开始时间按天分布", fontsize=15)
plt.show()
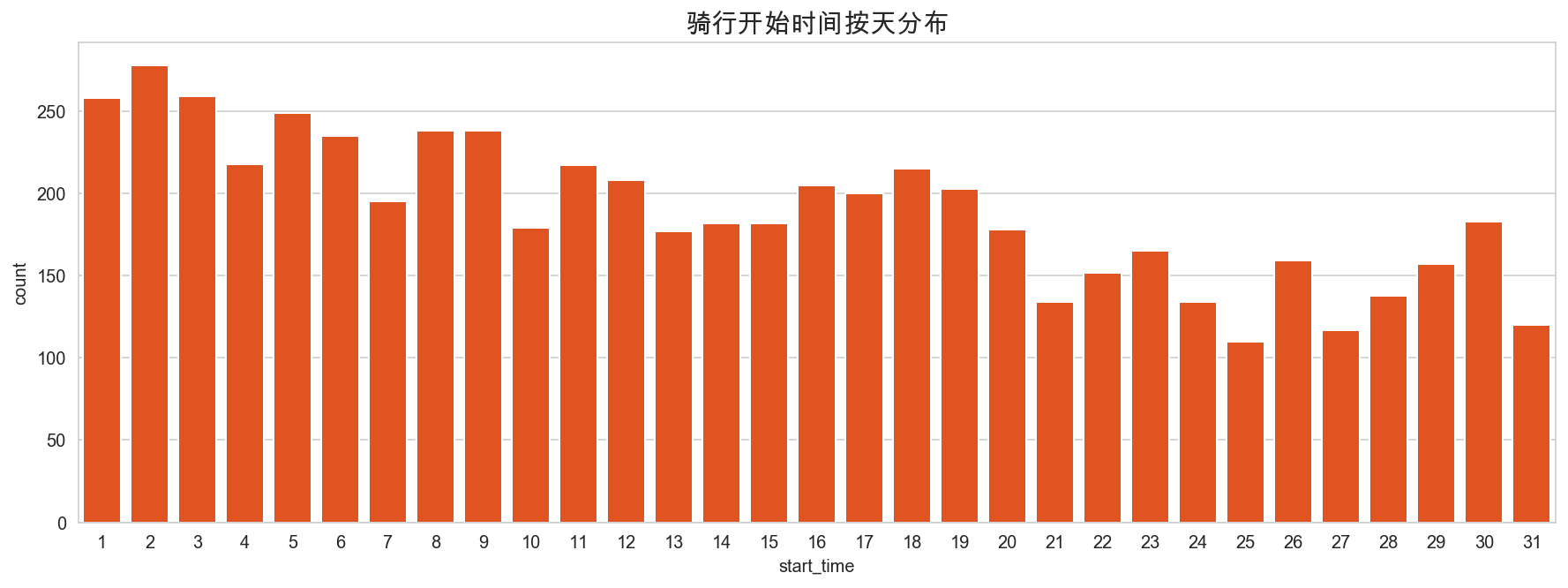
在月末骑行的人略少于月初和月中的人
# 查看骑行时间按周内天分布
plt.figure(figsize=(15,5))
sns.countplot(mobike['start_time'].dt.dayofweek, color='orangered')
plt.title("骑行开始时间按周内天分布", fontsize=15)
plt.show()
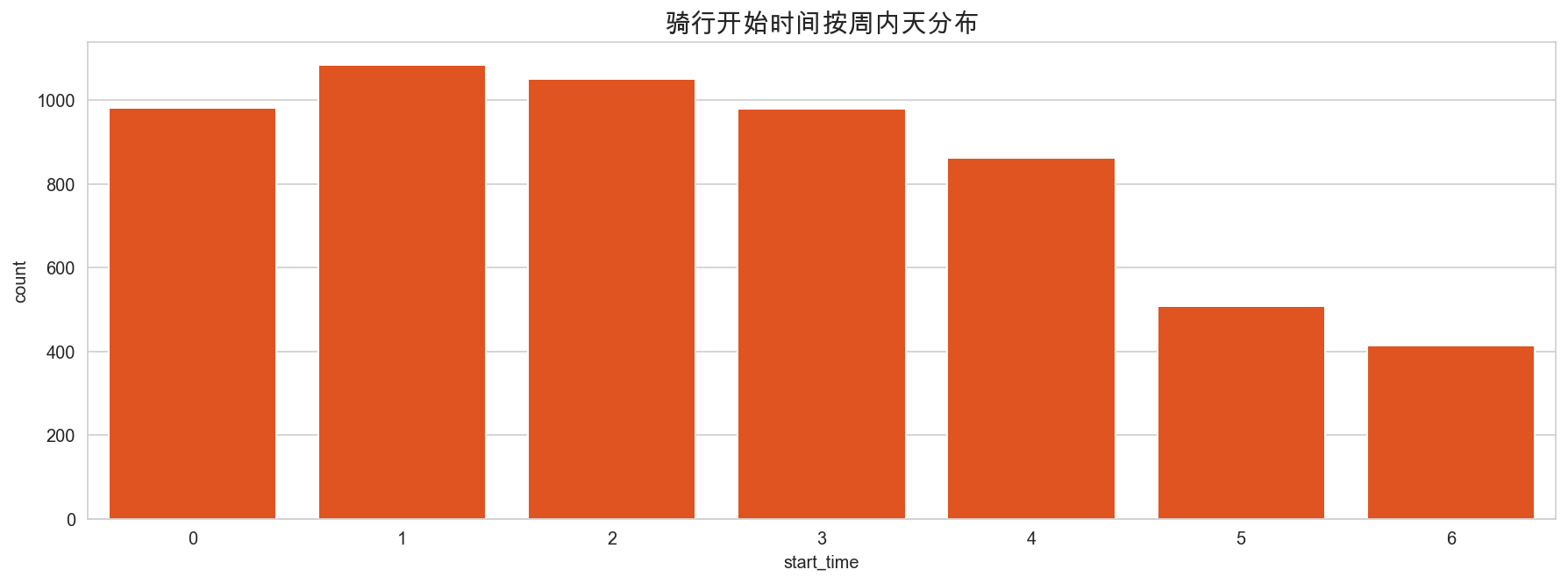
周末骑行的人少于周中的
# 查看骑行开始时间按小时分布
plt.figure(figsize=(15,5))
sns.countplot(mobike['start_time'].dt.hour, color='orangered')
plt.title("骑行开始时间按小时分布", fontsize=15)
plt.show()
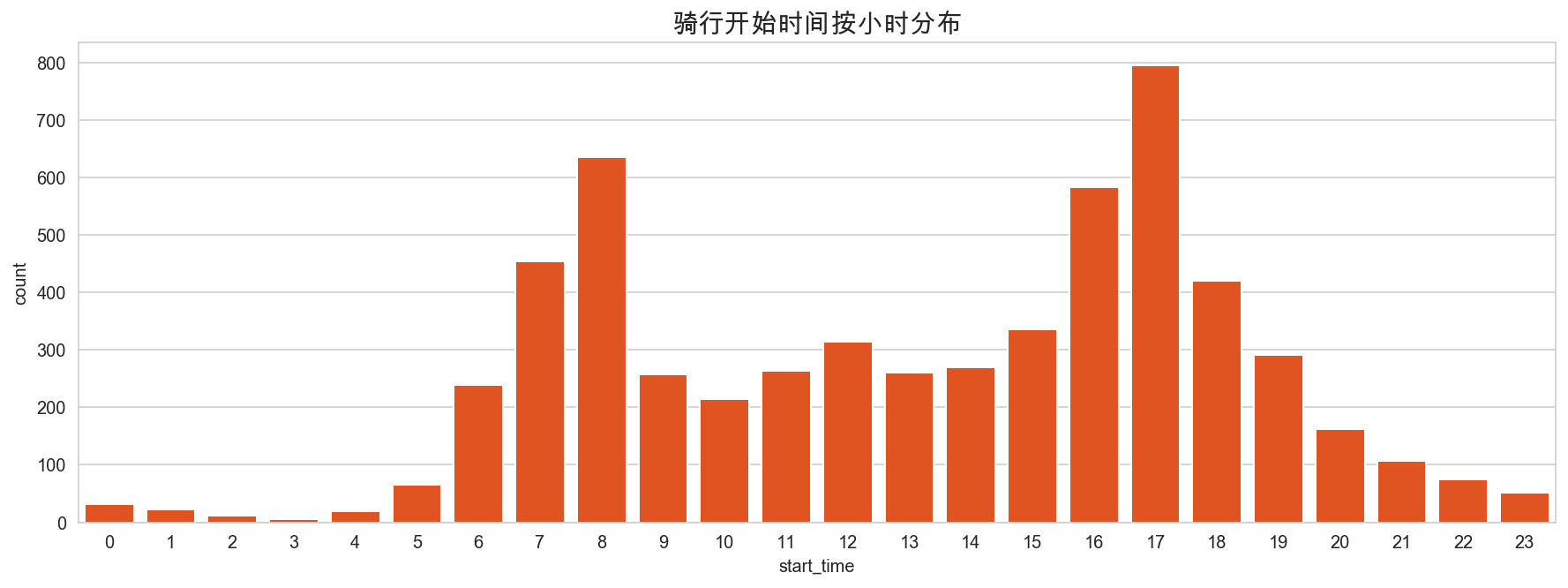
早晚高峰的骑车数量明显增多
3.5 骑行时长
plt.figure(figsize=(15,5))
sns.distplot(mobike['timeduration'], color='orangered')
plt.title("骑行时长分布 (分钟)", fontsize=15)
plt.show()
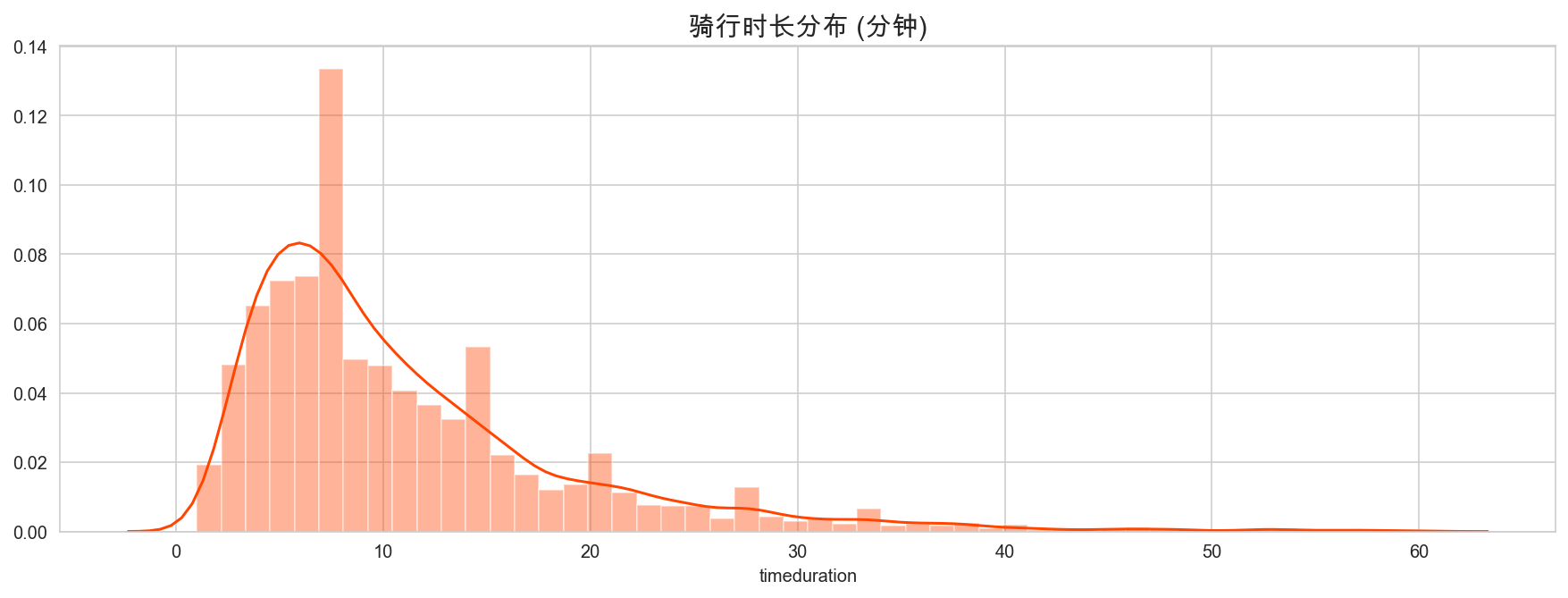
骑行时长在 5-15 分钟最多
3.6 骑行距离
plt.figure(figsize=(15,5))
sns.distplot(mobike['tripduration'], color='orangered')
plt.title("骑行距离分布", fontsize=15)
plt.show()
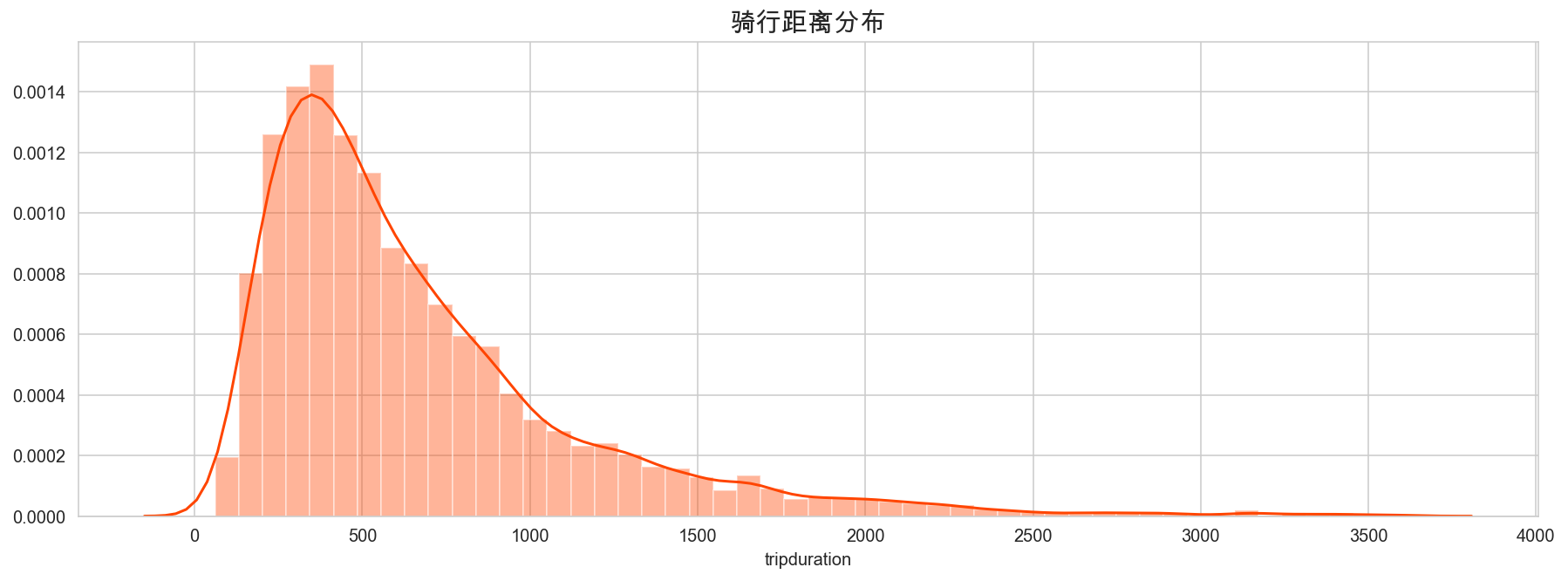
骑行距离在 200-800 米最多
3.7 平均骑行速度
plt.figure(figsize=(15,5))
sns.distplot(mb['speed'], color='orangered')
plt.title("平均骑行速度分布 (米/分钟)", fontsize=15)
plt.show()
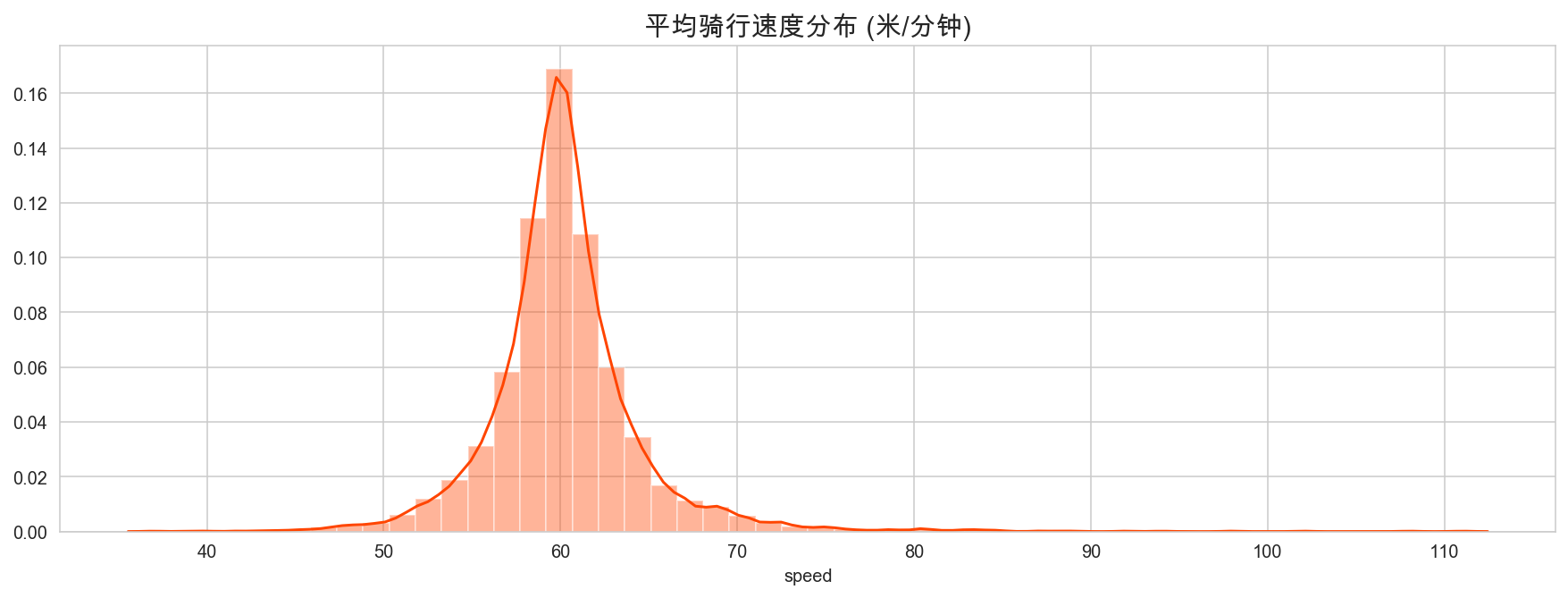
平均骑行速度集中在 60米/分钟 左右
4 - 聚类分析
4.1 - 数据准备
将类别变量使用 one-hot 编码方式进行编码
4.2 - K-Means 聚类模型
# 寻找最优 k
def KM_score(X, k: int) -> float:
"""返回轮廓系数 (Silhouette score)"""
model=KMeans(n_clusters=k, random_state=42)
model.fit(X)
X_cluster = model.fit_predict(X)
score = metrics.silhouette_score(X, X_cluster)
return score
# 计算轮廓系数
score_dict = {}
for i in range(2, 10):
score_dict[i] = KM_score(X, i)
# 绘制轮廓系数图像
plt.figure(figsize=(15,5))
plt.plot(score_dict.keys(), score_dict.values(), linestyle='--', marker='o')
plt.title("轮廓系数折线图", fontsize=15)
plt.show()
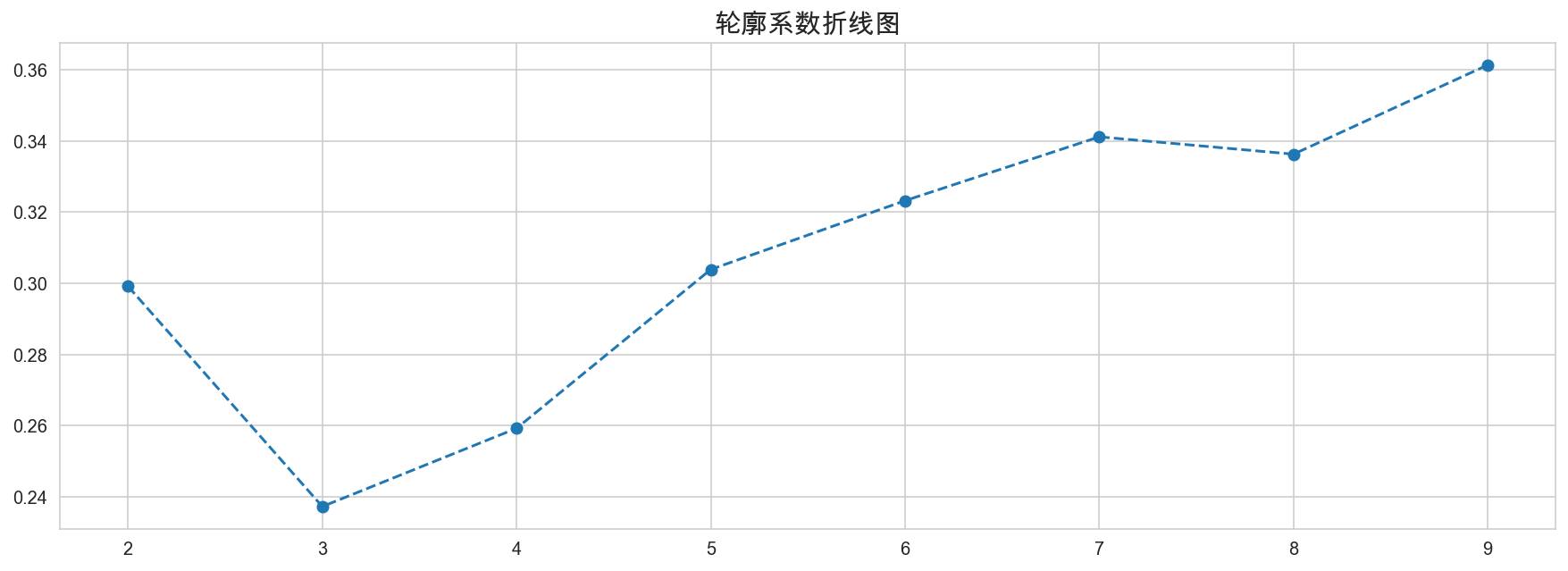
# 为了观察分群效果,我们选择分成7组
model = KMeans(n_clusters=7, random_state=42)
model.fit(X)
KMeans(n_clusters=7, random_state=42)
mobike_cluster['cluster'] = model.labels_
mobike_cluster['cluster'].value_counts()
0 1399
2 1167
6 1114
3 783
1 703
5 538
4 179
Name: cluster, dtype: int64
4.3 查看聚类效果
>> mobike_cluster.groupby(['cluster'])['timeduration'].describe()
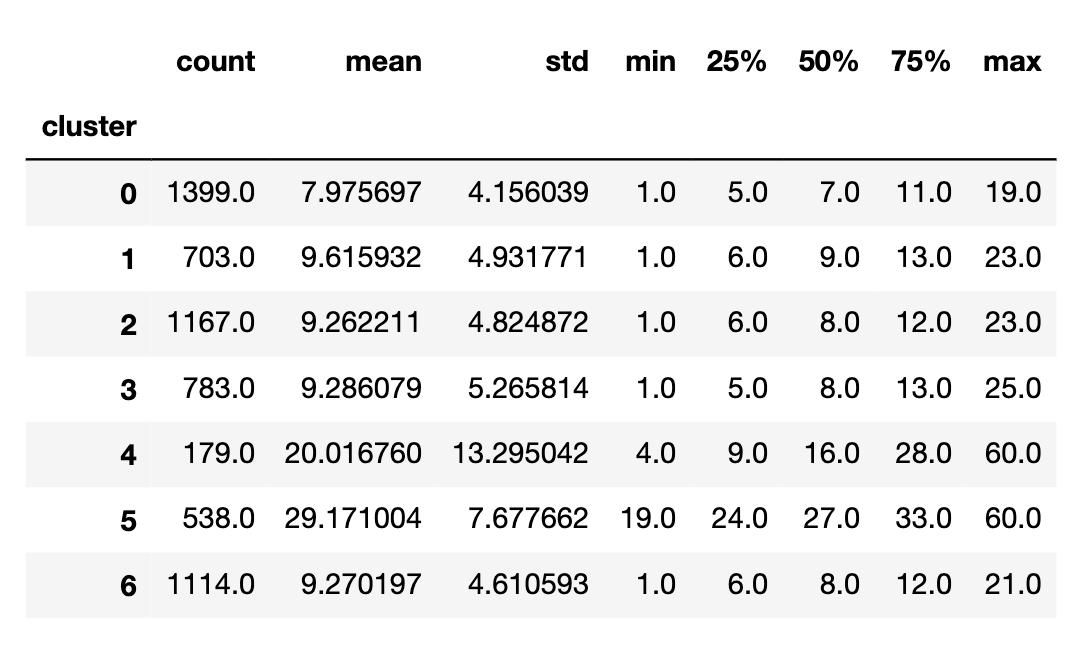
>> mobike_cluster.groupby(['cluster'])['tripduration'].describe()
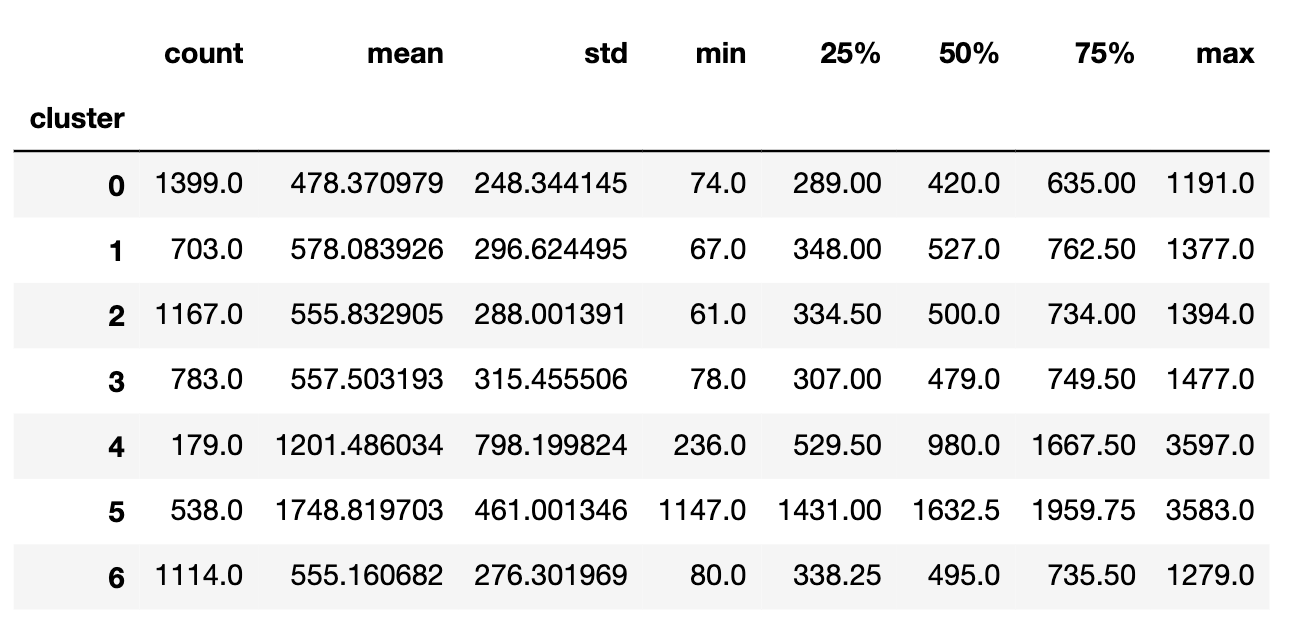
4,5 组骑行时间较长,骑行距离也远
5 - 聚类业务解读
>> pd.DataFrame(model.cluster_centers_, columns=mobike_cluster.columns[:8])
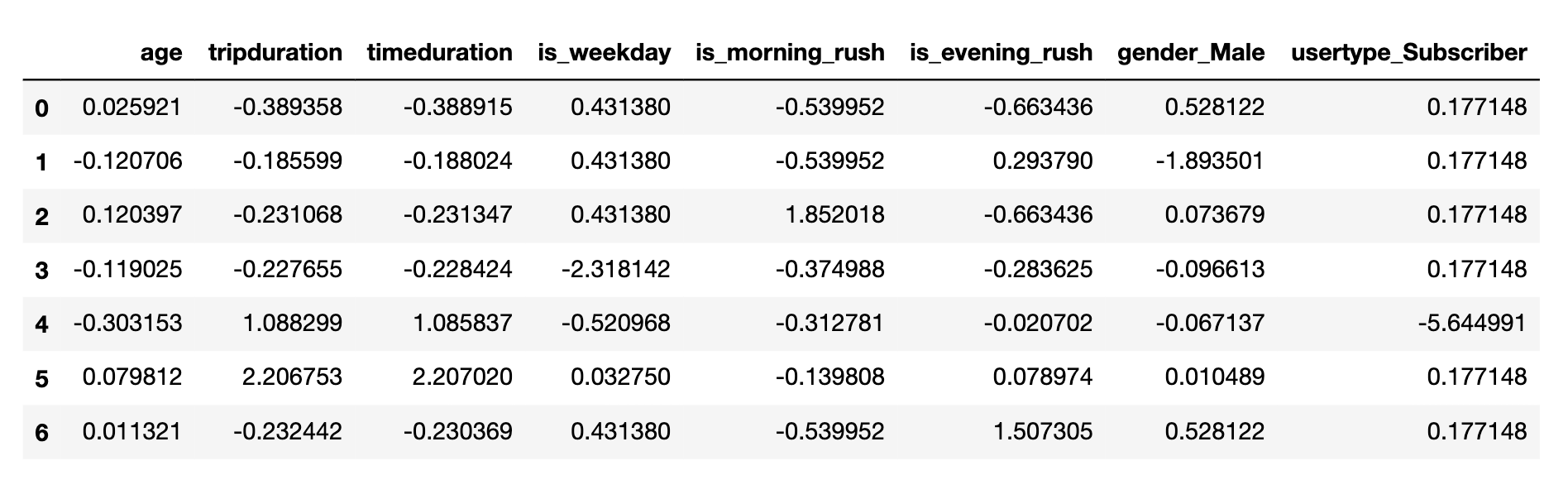
聚类分组分析
- 4, 5 组的骑行时间和距离较大
- 3 组主要在周末骑行
- 2 组主要是早高峰骑行的用户
- 6 组主要是晚高峰用户
- 1 组女性用户较多
- 4 组主要是非订阅用户
总结
- 通过用户基本数据分析,我们的大部分用户为25-35的年轻人,在工作日的早晚高峰进行短距离骑行,我们可针对此类人气进行精准营销,进行推送和优惠券的发放来提高业务收入
- 通过聚类分析,我们可以得到各组用户的特征从而给他们打上标签,例如‘晚高峰用户’,之后可在晚高峰前给予信息推送,从而提高单车的使用率